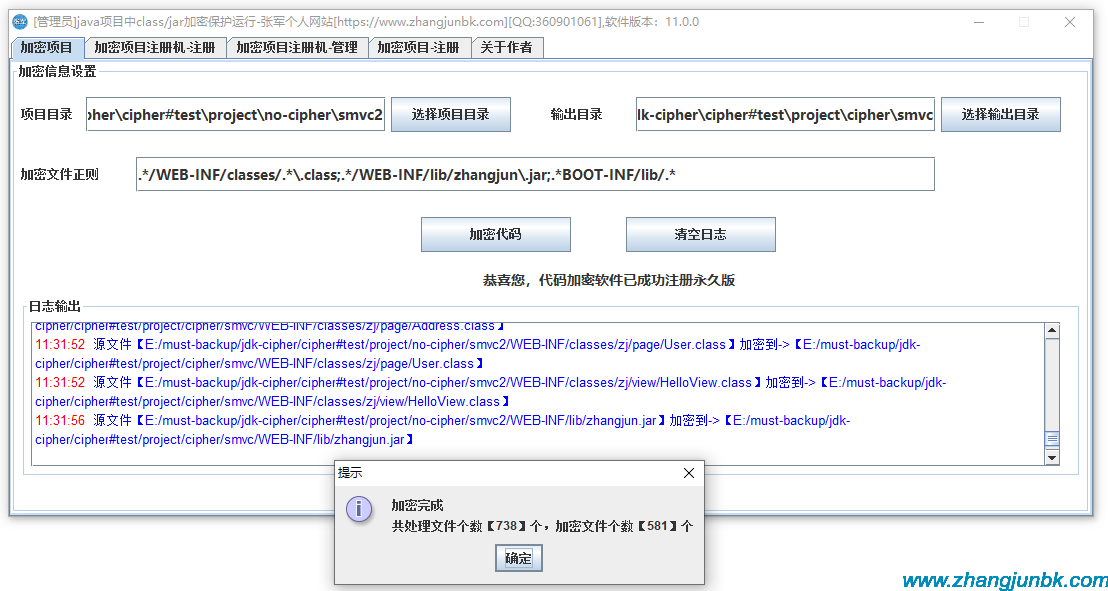
前言:如果沒有深入了解LSTM原理及結構,推薦看下面兩篇blog,不在贅述:從深度學習到LSTM:https://blog.csdn.net/hz371071798/article/details/82532183LSTM結構詳解:https://blog.csdn.net/zhangbaoanhadoop/article/details/81952284正文開始,簡單寫一下編程實現:注:和上文一樣,data直接采用facebook的prophet時序算法
系統 2019-09-27 17:47:30 3504
關于截斷正態分布(truncatednormaldistribution)這里不再贅述,簡言之就是在均值和方差之外,再指定正態分布隨機數群的上下限,如[μ-3σ,μ+3σ],上代碼:importmatplotlib.pyplotaspltimportscipy.statsasstatsimportpylabfrompylabimport*mu,sigma=5,0.7lower,upper=mu-2*sigma,mu+2*sigma#截斷在[μ-2σ,μ+2
系統 2019-09-27 17:45:44 3487
1.二維數組中的查找題目描述在一個二維數組中(每個一維數組的長度相同),每一行都按照從左到右遞增的順序排序,每一列都按照從上到下遞增的順序排序。請完成一個函數,輸入這樣的一個二維數組和一個整數,判斷數組中是否含有該整數。classSolution:#array二維列表defFind(self,target,array):rowNum=len(array)columnNum=len(array[0])forpinrange(rowNum):forqinran
系統 2019-09-27 17:48:38 3470
一、目的1、畫一個立方體并自動旋轉。二、程序運行結果三、畫立方體畫一個立方體,需要八個頂點的數據。一個正方體如何畫出來,需要一個面一個面的畫,那么正方體有6個面,而每個面呢?是一個正方形,我們把正方形劃分為兩個三角形,這個三角形是opengl中最小的片元了。立方體有六個面,每個面兩個三角形,也就是12個三角形,每個三角形3個頂點,于是要定義36個頂點。使用語句glDrawArrays(GL_TRIANGLES,0,36)畫出36個點。四、glVertexA
系統 2019-09-27 17:57:23 3464
開發版本:python2.7@resource_manage.route("/batch_import_data",methods=["POST"])#接口形式@auth_decorator.requires_auth#驗證用戶信息defbatch_import_data():"""批量導入*file:文件*mode:is_device/is_station:return:"""the_file=request.files.get("file")mode=
系統 2019-09-27 17:48:47 3461
前言文不如字,字不如表,表不如圖”,說的就是可視化的重要性。從事與數據相關的工作者經常會作一些總結或展望性的報告,如果報告中密密麻麻都是文字,相信聽眾或者老板一定會厭煩;如果報告中呈現的是大量的圖形化結果,就會受到眾人的喜愛,因為圖形更加直觀、醒目。本章內容的重點就是利用Python繪制常見的統計圖形,例如條形圖、餅圖、直方圖、折線圖、散點圖等,通過這些常用圖形的展現,將復雜的數據簡單化。這些圖形的繪制可以通過matplotlib模塊、pandas模塊或者
系統 2019-09-27 17:48:28 3447
一步一步講解和實現ASR中常用的語音特征——FBank和MFCC的提取,包括算法原理、代碼和可視化等。完整JupyterNotebook鏈接:https://github.com/Magic-Bubble/SpeechProcessForMachineLearning/blob/master/speech_process.ipynb文章目錄語音信號的產生準備工作1.導包2.繪圖工具3.數據準備預加重(Pre-Emphasis)分幀(Framing)加窗(W
系統 2019-09-27 17:54:33 3443
這是一篇使用Python模擬登陸天眼查網站的詳細介紹,天眼查網站上有許多的企業信息,因此抓取天眼查數據十分重要,本文使用selenium模擬登陸天眼查網站。其實我之前就想寫這個python模擬登錄網站的,因為之前爬蟲用的時候感覺還挺好用的,后來想學一下R爬蟲再來用R寫的,結果最近的爬蟲還是用的python,so,給大家用python講解咯。今天給大家講的是模擬登錄“天眼查”這個網站,網站登錄頁面就是下面這樣。我們用的工具就是PyCharm編譯器,類似于R里
系統 2019-09-27 17:56:13 3383
楊輝三角,是二項式系數在三角形中的一種幾何排列每個數等于它上方兩數之和。每行數字左右對稱,由1開始逐漸變大。第n行的數字有n項。第n行數字和為2n-1。第n行的m個數可表示為C(n-1,m-1),即為從n-1個不同元素中取m-1個元素的組合數。第n行的第m個數和第n-m+1個數相等,為組合數性質之一。每個數字等于上一行的左右兩個數字之和。可用此性質寫出整個楊輝三角。即第n+1行的第i個數等于第n行的第i-1個數和第i個數之和,這也是組合數的性質之一。即C(
系統 2019-09-27 17:55:45 3381
首先你得安裝netCDF4這個庫(pipinstall)簡單讀取如下可以看到dimensions(sizes):longitude(480),latitude(241),time(480)variables(dimensions):float32longitude(longitude),float32latitude(latitude),int32time(time),int16z(time,latitude,longitude)這是一個三維數據集,空間兩
系統 2019-09-27 17:55:06 3370
原因:__str__()這個特殊方法將對象轉換為字符串的結果效果圖:這種形式的原因_第1張圖片"src="https://img.it610.com/image/info11/402d664b5c9049e8b4c58b5ede570676.png"width="753"height="359"style="border:1pxsolidblack;"/>代碼:#定義一個Person類classPerson(object):"""人類"""def__ini
系統 2019-09-27 17:37:37 3352
第一步:首先定義一個視圖函數,用于提供數據,實現每頁顯示數據個數,返回每頁請求數據fromdjango.shortcutsimportrenderfromdjango.core.paginatorimportPaginator#Django內置分頁功能模塊defindex(request):#提供json數據resp={"id":10000,"username":"user-0","sex":"女","city":"城市-0","sign":"簽名-0",
系統 2019-09-27 17:56:48 3349
一.分散性聚類(kmeans)算法流程:1.選擇聚類的個數k.2.任意產生k個聚類,然后確定聚類中心,或者直接生成k個中心。3.對每個點確定其聚類中心點。4.再計算其聚類新中心。5.重復以上步驟直到滿足收斂要求。(通常就是確定的中心點不再改變。優點:1.是解決聚類問題的一種經典算法,簡單、快速2.對處理大數據集,該算法保持可伸縮性和高效率3.當結果簇是密集的,它的效果較好缺點1.在簇的平均值可被定義的情況下才能使用,可能不適用于某些應用2.必須事先給出k(
系統 2019-09-27 17:54:36 3335
Numpy數組可以直接切片,但是普通的Python二維數組不行。方法一a=[[1,2],[3,4]]b=[i[0]foriina]#從a中的每一行取第一個元素。print(b)[1,4]方法二a=[[1,2],[3,4]]b=list(zip(*a))print(b)[(1,3),(2,4)]
系統 2019-09-27 17:49:20 3326
計算一串數組的均值、中位數、標準差#!/usr/bin/envpython#-*-coding:utf-8-*-'''@author:FIGTHING@file:DataMining.py@function:@software:Pycharm@time:2019/06/13/15:40'''importnumpyasnpage=[23,23,27,27,39,41,47,49,50,52,54,54,56,57,58,58,61]fat=[9.5,26.5
系統 2019-09-27 17:52:08 3319